引言
大数据的领域非常广泛,往往使想要开始学习大数据及相关技术的人望而生畏。大数据技术的种类众多,这同样使得初学者难以选择从何处下手。
这正是我想要撰写本文的原因。本文将为你开始学习大数据的征程以及在大数据产业领域找到工作指明道路,提供帮助。目前我们面临的最大挑战就是根据我们的兴趣和技能选定正确的角色。
为了解决这个问题,我在本文详细阐述了每个与大数据有关的角色,同时考量了工程师以及计算机科学毕业生的不同职位角色。
我尽量详细地回答了每一项人们在学习大数据过程中遇到或可能会遇到的问题。为帮助你根据兴趣选择发展途径,我添加了一组树图,相信会对你找到正确的途径有所帮助。

注释:学习之路树状图
在这个树状图的帮助下,你可以根据你的兴趣和目标选择路径。然后,你可以开始学习大数据的旅程了。
目录表
1.如何开始?
2.在大数据领域有哪些职位需求?
3.你的领域是什么,适合什么方向?
4.勾勒你在大数据领域的角色
5.如何成为一名大数据工程师?
o什么是大数据行业术语?
o你需要了解的系统和结构
o学习去设计解决方案并且学习相关技术
6.大数据学习路径
7.资源
1.如何开始?
人们想开始学习大数据的时候,最常问我的问题是,“我应该学Hadoop(hadoop是一款开源软件,主要用于分布式存储和计算,他由HDFS和MapReduce计算框架组成的,他们分别是Google的GFS和MapReduce的开源实现。由于hadoop的易用性和可扩展性,因此成为最近流行的海量数据处理框架。hadoop这个单词来源于其发明者的儿子为一个玩具大象起的名字。),分布式计算,Kafka(Kafka是由LinkedIn开发的一个分布式基于发布/订阅的消息系统),NoSQL(泛指非关系型的数据库)还是Spark(Spark是一种与Hadoop相似的开源集群计算环境,但是两者之间还存在一些不同之处)?”
而我通常只有一个答案:“这取决于你究竟想做什么。”
因此,让我们用一种有条理的方式来解决这个问题。我们将一步步地探索这条学习之路。
2.在大数据行业有哪些职业需求?
在大数据行业中有很多领域。通常来说它们可以被分为两类:
大数据工程
大数据分析
这些领域互相独立又互相关联。
大数据工程涉及大量数据的设计,部署,获取以及维护(保存)。大数据工程师需要去设计和部署这样一个系统,使相关数据能面向不同的消费者及内部应用。
而大数据分析的工作则是利用大数据工程师设计的系统所提供的大量数据。大数据分析包括趋势、图样分析以及开发不同的分类、预测预报系统。
因此,简而言之,大数据分析是对数据的高级计算。而大数据工程则是进行系统设计、部署以及计算运行平台的顶层构建。
3.你的领域是什么,适合什么方向?
现在我们已经了解了行业中可供选择的职业种类,让我们想办法来确定哪个领域适合你。这样,我们才能确定你在这个行业中的位置。
通常来说,基于你的教育背景和行业经验我们可以进行如下分类:
教育背景(包括兴趣,而不一定与你的大学教育有关)
计算机科学
数学
行业经验
新人
数据学家
计算机工程师(在数据相关领域工作)
因此,通过上面的分类,你可以把自己的领域定位如下:
例1:“我是一名计算机科学毕业生,不过没有坚实的数学技巧。”
你对计算机科学或者数学有兴趣,但是之前没有相关经验,你将被定义为一个新人。
例2:“我是一个计算机科学毕业生,目前正从事数据库开发工作。”
你的兴趣在计算机科学方向,你适合计算机工程师(数据相关工程)的角色。
例3:“我正作为数据科学家从事统计工作。”
你对数学领域有兴趣,适合数据科学家的职业角色。
因此,参照着定位你的领域吧。
(此处定义的领域对你确定在大数据行业的学习路径至关重要。)
4.根据领域规划你的角色
现在你已经确定了你的领域,下一步,让我们规划出你要努力的目标职位吧。
如果你有卓越的编程技巧并理解计算机如何在网络(基础)上运作,而你对数学和统计学毫无兴趣,在这种情况下,你应该朝着大数据工程职位努力。
如果你擅长编程同时有数学或者统计学的教育背景或兴趣,你应该朝着大数据分析师职位努力。
5.如何成为一名大数据工程师
让我们先定义一下,一名受到行业承认的大数据工程师都需要学习和了解什么。首先以及最重要的一步是确认你的需求。你不能在不清楚个人需求的情况下直接开始学习大数据。否则,你将一直盲人摸象。
为了明确你的需求,你必须了解常用的大数据术语。所以让我们来看一下大数据到底意味着什么?
5.1大数据术语
大数据工程通常包括两个方面–数据需求以及处理需求。
5.1.1数据需求术语
结构:你应该知道数据可以储存在表中或者文件中。储存在一个预定义的数据模型(即拥有架构)中的数据称为结构化数据。如果数据储存在文件中且没有预定义模型,则称为非结构化数据。(种类:结构化/非结构化)。
容量:我们用容量来定义数据的数量。(种类:S/M/L/XL/XXL/流)
Sink吞吐量:用系统所能接受的数据率来定义Sink吞吐量。(种类:H/M/L)
源吞吐量:定义为数据更新和转化进入系统的速度。(种类:H/M/L)
5.1.2处理需求术语
查询时间:系统查询所需时间。(种类:长/中/短)
处理时间:处理数据所需时间。(种类:长/中/短)
精度:数据处理的精确度。(种类:准确/大约)
5.2你需要知道的系统和架构
情景1:
为分析一个公司的销售表现需要设计一个系统,即创建一个数据池,数据池来自于多重数据源,比如客户数据、领导数据、客服中心数据、销售数据、产品数据、博客等。
5.3学习设计解决方案和技术
情节1的解决方案:销售数据池
(这是我的个人解决方案,如果你想到一个更高明的解决方案请在下面分享一下)
那么,一个数据工程师会怎样解决这个问题呢?
需要记住的一点是,大数据系统的目的不仅仅是无缝整合各种来源的数据,而使其可用,同时它必须能使得,用于开发应用系统的数据的分析和利用变得简单迅速和易得(在这个案例中是智能控制面板)。
定义最后的目标:
通过整合各种来源的数据创建一个数据池。
每隔一定时间自动更新数据(在这个案例中可能是一周一次)。
可用于分析的数据(在记录时间内,甚至可能是每天)
易得的架构和无缝部署的分析控制面板。
既然我们知道了我们最后的目标,让我们尽量用正式术语制定我们的要求吧。
5.3.1数据相关要求
结构:大部分数据是结构化的,并具有一个定义了的数据模型。但数据源如网络日志,客户互动/呼叫中心数据,销售目录中的图像数据,产品广告数据等是非结构化的。图像和多媒体广告数据的可用性和要求可能取决于各个公司。
结论:结构化和非结构化数据
大小:L或XL(选择Hadoop)
Sink吞吐量:高
质量:中等(Hadoop&Kafka)
完整性:不完整
5.3.2处理相关要求
查询时间:中至长
处理时间:中至短
精度:准确
随着多个数据源的集成,重要的是要注意不同的数据将以不同的速率进入系统。例如,网络日志可用高颗粒度连续流进入系统。
基于上述我们对系统要求的分析,我们可以推荐以下大数据体系。
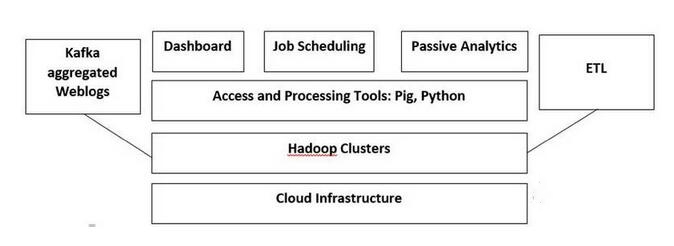
6.大数据学习路径
现在,你已经对大数据行业,大数据从业人员的不同角色和要求有所了解。我们来看看你应该遵循哪条路来成为一名大数据工程师。
我们知道大数据领域充斥着多种技术。因此,你学习与你的大数据工作角色相关的技术非常重要。这与任何常规领域有点不同,如数据科学和机器学习中,你可以从某些地方开始并努力完成这一领域内的所有工作。
下面你会发现一个你应该通过的树状图,以找到你自己的路。即使树状图中的一些技术被指向是数据科学家的强项,但是如果你走上一条路,知道所有的技术直到“树叶节点”总是很好的。该树状图源自lambda架构范例。

注释:学习之路树状图
任何想要调配应用程序的工程师必须知道的基本概念之一是Bash脚本编程。你必须对linux和bash脚本编程感到舒适。这是处理大数据的基本要求。
核心是,大部分大数据技术都是用Java或Scala编写的。但是别担心,如果你不想用这些语言编写代码,那么你可以选择Python或者R,因为大部分的大数据技术现在都支持Python和R。
因此,你可以从上述任何一种语言开始。我建议选择Python或Java。
接下来,你需要熟悉云端工作。这是因为如果你没有在云端处理大数据,没有人会认真对待。请尝试在AWS,softlayer或任何其他云端供应商上练习小型数据集。他们大多数都有一个免费的层次,让学生练习。如果你想的话,你可以暂时跳过此步骤,但请务必在进行任何面试之前在云端工作。
接下来,你需要了解一个分布式文件系统。最流行的分布式文件系统就是Hadoop分布式文件系统。在这个阶段你还可以学习一些你发现与你所在领域相关的NoSQL数据库。下图可以帮助你选择一个NoSQL数据库,以便根据你感兴趣的领域进行学习。
到目前为止的路径是每个大数据工程师必须知道的硬性基础知识。
现在,你决定是否要处理数据流或静止的大量数据。这是用于定义大数据(Volume,Velocity,Variety和Veracity)的四个V中的两个之间的选择。
那么让我们假设你已经决定使用数据流来开发实时或近实时分析系统。之后你应该采取卡夫卡(kafka)之路,或者还可以采取Mapreduce的路径。然后你按照你自己创建的路径。请注意,在Mapreduce路径中,你不需要同时学习pig和hive。只学习其中之一就足够了。
总结:通过树状图的方式。
从根节点开始,并执行深度优先的通过方式。
在每个节点停止查验链接中给出的资源。
如果你有充足的知识,并且在使用该技术方面有相当的信心,那么请转到下一个节点。
在每个节点尝试完成至少3个编程问题。
移动到下一个节点。
到达树叶节点。
从替代路径开始。
最后一步(#7)阻碍你!说实话,没有应用程序只有流处理或慢速延迟数据处理。因此,你在技术上需要成为执行完整的lambda架构的高手。
另外,请注意,这不是学习大数据技术的唯一方法。你可以随时创建自己的路径。但这是一个可以被任何人使用的路径。
如果你想进入大数据分析世界,你可以遵循相同的路径,但不要尝试让所有东西都变得完美。
对于能够处理大数据的数据科学家,你需要在下面的树状图中添加一些机器学习渠道,并将重点放在机器学习渠道上,而不是下面提供的树状图。但我们可以稍后讨论机器学习渠道。
根据你在上述树状图中使用的数据类型,添加选择的NoSQL数据库。

该表格表示数据存储类型要求及相应的软件选择
如你所见,有大量的NoSQL数据库可供选择。所以它常常取决于你将要使用的数据类型。
而且为了给采用什么类型的NoSQL数据库提供一个明确的答案,你需要考虑到你的系统需求,如延迟,可用性,弹性,准确性当然还有你当前处理的数据类型。
7.资源
初学者的Bash指南,来自MachteltGarrels
1.Python
让每个人变成python专家,来自Coursera
用Python学数据科学之路,来自Coursera
2.Java
Java编程简介1:开始使用Java编码,来自Udemy
中级和高级Java编程,来自Udemy
Java编程介绍2,来自Udemy
面向对象Java编程:数据结构和超越专业化,来自Coursera
3.云
大数据技术基础,来自亚马逊网络服务
AWS上的大数据,来自亚马逊网络服务
4.HDFS
大数据和Hadoop要点,来自Udemy
大数据基础,来自大数据大学
Hadoop入门工具包
ApacheHadoop文档
书--Hadoop集群部署
5.ApacheZookeeper
ApacheZookeeper文档
书-Zookeeper
6.ApacheKafka
完整初学者ApacheKafka课程
学习ApacheKafka基础和高级主题
ApacheKafka文档
书-学习ApacheKafka
7.SQL
用MySQL管理大数据
SQL课程
PostgreSQL初学者指南
高性能MySQL
8.Hive
使用Hive访问Hadoop数据
学习ApacheHadoop生态系统Hive
ApacheHive文档
Hive编程
9.Pig
ApachePig101,来自大数据大学
用Hadoop与ApachePig编程
ApachePig文档
书-Pig编程
10.ApacheStorm
使用ApacheStorm实时分析
ApacheStorm文档
11.ApacheKinesis
ApacheKinesis文档
AmazonKinesis通过AmazonWebServices流式浏览开发人员资源
亚马逊KinesisStreams开发人员资源,来自亚马逊网络服务
12.ApacheSpark
数据科学、工程与Apache
ApacheSpark文档
书-学习Spark
13.ApacheSparkStreaming
ApacheSparkStreaming文档
尾注
我希望你们喜欢阅读这篇文章。借助这种学习途径,你将能够踏上你在大数据行业的旅程。我已经叙述了大部分你找工作会要求的主要概念。
 联系我们请点击:
联系我们请点击:



